
[NLP] 기계 번역을 위한 유의성 검정 (significance test for machine translation)
by Jeonghyeok Park
안녕하세요.
이번 포스팅에서 말씀드릴 내용은 기계 번역을 위한 유의성 검정입니다.
이 포스팅은 개인적인 메모 정도로 쓰는 내용이라 배경지식에 대한 설명은 배제하고 핵심만 쓸 예정입니다.
목표는 “기계 번역에 대한 논문, 리포트에서 제안한 모델에 대한 결과를 제시할 때 BLEU significance를 어떻게 얻는가?” 입니다.
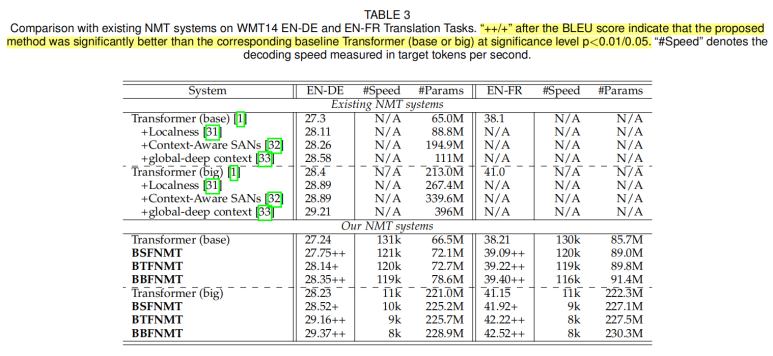
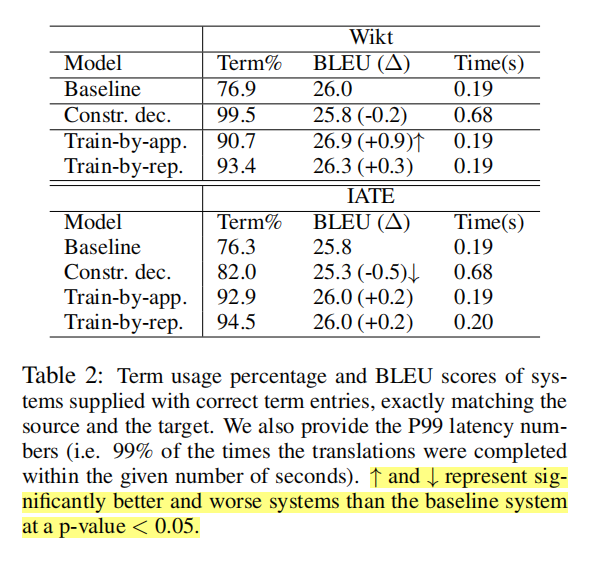
위는 기계 번역에 관련된 논문에서 발췌된 실험 결과 테이블입니다. ++/+ 또는 화살표로 significance test의 결과를 추가합니다. 노랗게 하이라이트된 부분이 그 설명인데요. 이 이상의 설명을 추가하는 논문은 없습니다.
올해 8월에 제출한 paper가 다행히 통과되었고, reviewer들에게 몇가지 코멘트를 받았습니다. 그 중에 다음과 같은 내용이 있었습니다. “This work can only achieve a small improvement. It would be great to do a significance test.” 이 논문에서 제안한 모델은 작은 성능 향상(BLEU - 기계 번역 평가 메트릭)을 달성했다. significance test가 진행되면 좋을 것 같다.
여지껏 논문을 읽으면서 p-value, 실험 결과 테이블 옆의 ++ 표시 등 많이 봐왔습니다. 사실 관심도 있어서 찾아보긴 했지만 귀무가설..t-value, p-value, 확률 등등 일단 용어부터 이해가 되지 않아 읽고 그런게 있구나하고 넘어갔습니다. 설명도 전부 동전을 던지는 예시를 들어서 실제로 어떻게 적용할지에 대해서는 전혀 감이 오지 않았습니다. 사실 논문에서 모델 성능 평가가 정말 중요한 부분인데, 그 동안 성능에만 매달려 모델 변형, 하이퍼 파라미터 조정 등에만 신경썼던 것 같습니다. 반성합니다. 이번에 논문 camera-ready 버전을 준비하면서 significance test, effect size 등 좀 찾아보긴 했지만, 아직 전부 읽어보지는 못했고 용어도 아직 정확히는 이해 못했습니다. 졸업 논문만 마무리하고 며칠 매달려서 읽어보고 보충하도록 하겠습니다.
다시 본론으로 돌아와서.. 일단 기계 번역에 대한 유의성 검사에 대한 한 줄 정의는 Test set에 대하여 Model A의 결과(BLUE score)가 Baseline B의 결과(BLUE score)보다 높다고 해서 정말로 유의미한 것인가? 에 대한 검증입니다.
그럼 어떻게 테이블에 ++/+ (significance test)를 추가할 수 있는가 간단히 정리해보겠습니다. Korean->English 기계 번역에 대해 제안한 Model A와 Baseline B가 있습니다. 그리고 Test set의 크기는 2000이라고 가정하겠습니다.
위에 테이블을 보시면 significance test에서 등장하는 p-value라는 값이 있습니다. (참고로, p-value 0.01은 ++를, 0.05는 +를 가르킵니다.) p-value의 정의는 “귀무가설에 대한..” 그렇습니다. 아래에 예시를 보시면 어떤 것인지 바로 아실 수 있습니다.
예를 들어, Baseline B의 BLEU score가 30.50, Model A의 BLUE score가 31.27이 나왔습니다. Model A의 성능이 0.77 더 높습니다. 나쁘지 않은 결과입니다. 하지만 testset의 한 문장 한 문장 대해서 0.77만큼의 성능 향상이 있다고 볼 수 있을까요? 분명 그렇지 않을 겁니다. 어떤 문장의 번역 성능은 오히려 떨어졌을 수도 있습니다. 이 번역 성능에 대한 유의미성을 증명하기 위해 significance test를 수행합니다.
기계 번역 결과(BLEU)에 대한 significance test는 다음과 같은 절차로 진행됩니다.
-
test set에 대해서 일정량의 문장을 random sampling한다. 예를 들어, 100 문장을 랜덤하게 뽑는다고 가정하겠습니다.
-
sampling된 문장에 대한 BLEU score 계산합니다.
-
과정 1, 2를 n 번 반복합니다. n을 1000으로 가정하겠습니다. 그렇다면 1000회에 대한 BLEU score를 얻을 수 있습니다. (31.30, 31.21, 30.90, …. 31.45)
Model A에 대한 BLEU score 결과 1000회 중에 Baseline B의 결과 30.50보다 낮은 경우가 50회 이하이다? -> + 10회 이하이다? -> ++ 50회/1000회 = 0.05 10회/1000회 = 0.01
이제 p-value가 무엇인지 아실거라고 생각합니다.
최근에는 significance test보다 effect size를 사용하는 것이 더 평가에 신빙성을 더 한다고 합니다.
significance test는 sampling size에 민감하게 반응하기 때문에 연구자가 sampling size를 어떤 값으로 정하느냐에 따라 결과가 바뀔 수도 있습니다.
이후에 관련 내용에 대해 더 보충하겠습니다.
이번 포스팅은 여기까지입니다.
감사합니다.
Subscribe via RSS
{kind=link}